

n-gram Language Models
언어 모델이란, 결국에는 그 다음으로 어떤 단어가 오는 것이 가장 자연스러운지를 확률로 보고 가장 높은 확률의 단어를 선택해서 문장을 구성하는 방식이다. 위 포스트에서는 n…
2025/03/10
NEW POST
Jinsoolve.
Categories
Tags
3월 안에는 꼭...
About
머신러닝에 사용하는 다양한 분류 모델들에 대해서 얘기해 보겠다.
SVM(Support Vector Machine)이라 불리는 이 분류 모델은 클래스를 구분하는 hyper-plane(초평면)과 이 hyper-plane에 가장 가까운 훈련 샘플 사이의 거리로 정의한다.
이러한 샘플을 서포트 벡터라고 한다.

SVM의 최적화 대상은 마진을 최대화 하는 것이다. 여기서 마진이란, 양성 쪽 hyper-plane과 음성 쪽 hyper-plane 사이의 거리를 뜻한다.
마진을 최대화하면 일반화 오차가 낮아지는 경향이 있기 때문에 마진의 최대화가 SVM의 최적화로 이어진다.
마진 최대화를 정확하게 이해하기 위해서는 초평면들의 수식 계산을 해야 하는데 결과적으로 가 최대화하고 싶은 마진을 의미한다는 결론이 도출된다.
따라서 SVM의 목적 함수는 샘플이 정확하게 �분류된다는 제약 조건 하에서 를 최대화함으로써 마진을 최대화하는 것이다.
결론적으로 SVM은 모든 양성 클래스 샘플은 양성 쪽 초평면 너머에, 모든 음성 클래스 샘플은 음성 쪽 초평면 너머에 있도록 하는 것이고 이를 수식으로 정리하면 다음과 같다.
SVM은 선형적으로 구분되지 않는 데이터에서 한계가 있습니다. 이를 해결하기 위해 슬랙 변수 를 사용하여 선형 제약을 완화시킨다.
이를 소프트 마진 분류라고 부른다. 슬랙 변수를 추가하여 수식화하면 다음과 같다.
C 는 으로 규제 파라미터 의 역수이다. 이 C를 줄이면 규제가 강해지고 이는 SVM에서 분산은 줄어들고 편향은 커진다(마진이 줄어들기 떄문).

python1from sklearn.svm import SVC 2 3# kernel='linear': 선형 분류 SVM을 사용하겠다. 4# C=1.0 : 규제의 역수 하이퍼 파라미터 5svm = SVC(kernel='linear', C=1.0, random_state=1) 6svm.fit(X_train_std, y_train) 7 8plot_decision_regions(X_combined_std, 9 y_combined, 10 classifier=svm, 11 test_idx=range(105, 150)) 12plt.xlabel('petal length [standardized]') 13plt.ylabel('petal width [standardized]') 14plt.legend(loc='upper left') 15plt.tight_layout() 16# plt.savefig('images/03_11.png', dpi=300) 17plt.show()
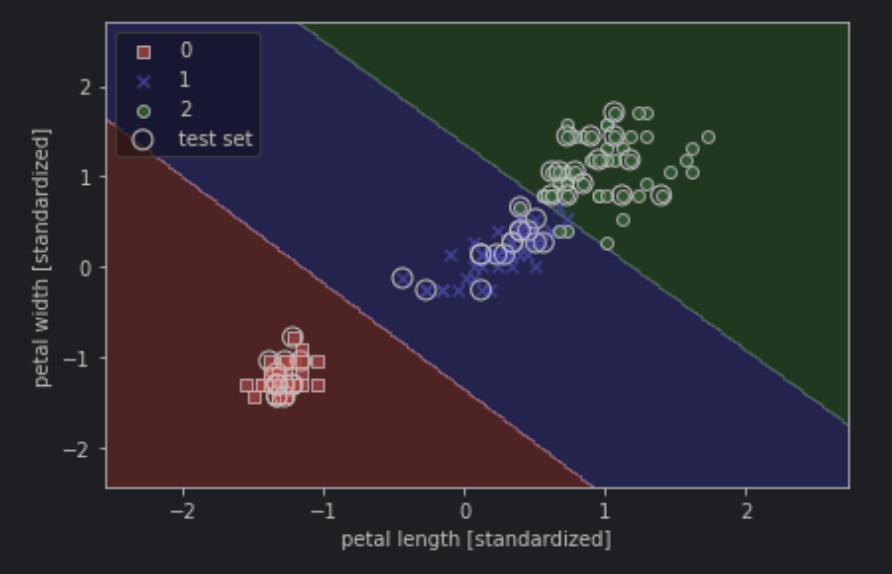
커널 SVM을 사용하��면 비선형 분류 문제도 해결이 가능하다.

위 그림처럼 비선형 분류 문제와 같은 경우는 일반적인 선형 SVM으로는 해결이 불가능한데 이를 커널 방법으로 해결할 수 있다.
쉽게 설명하면, 매핑 함수 를 사용하여 비선형 데이터들을 선형 구분이 가능한 고차원 공간에 투영하는 것이다.

위에 그림에서 보는 것처럼 원래 선형으로 분리가 안 되는 데이터셋을 선형적으로 분리할 수 있게 되었다.
하지만 이러한 매핑 방식은 새로운 특성을 만드는 계산 비용이 매우 비싸다는 단점이 있다. 이를 커널 기법(kernel trick)으로 해결한다.
수학적으로 여러 복잡한 과정이 있지만 여기서는 자세히 다루지 않고 간단한 과정을 요약하도록 하겠다.
실전에서 필요한 것은 점곱 를 로 바꾸는 것입니다.
이떄 점곱을 계산하는데 드는 비용을 절감하기 위해 커널 함수를 정의한다.
가장 널리 사용되는 커널 중 하나는 **방사 기저 함수(Radial Basis Function, RBF)**이다. 가우시안 커널이라고도 한다.
여기서 이고 이는 최적화 대상 파라미터가 아니다.
간단히 요약하면, 커널이란 용어를 샘플 간의 유사도 함수로 해석할 수 있도록 만드는 것이다. 실제 사용은 어떻게 하나 살펴보자.
python1# kernel을 Radial Basis Function으로 선택해 커널 기법을 이용해 커널 svm을 사용한다. 2# gamma는 위에서 사용한 파라미터로, 가우시안 구의 크기를 제한하는 매개변수이다. 3svm = SVC(kernel='rbf', random_state=1, gamma=0.10, C=10.0) 4svm.fit(X_xor, y_xor) 5plot_decision_regions(X_xor, y_xor, 6 classifier=svm) 7 8plt.legend(loc='upper left') 9plt.tight_layout() 10# plt.savefig('images/03_14.png', dpi=300) 11plt.show()
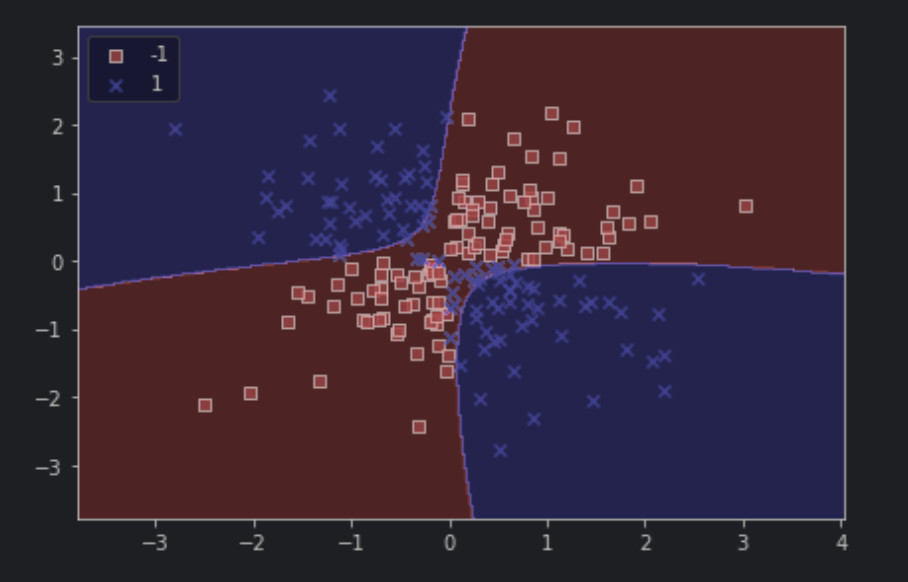
를 크게 하면 결정경계는 샘플에 가까워지고 구불구불해진다.
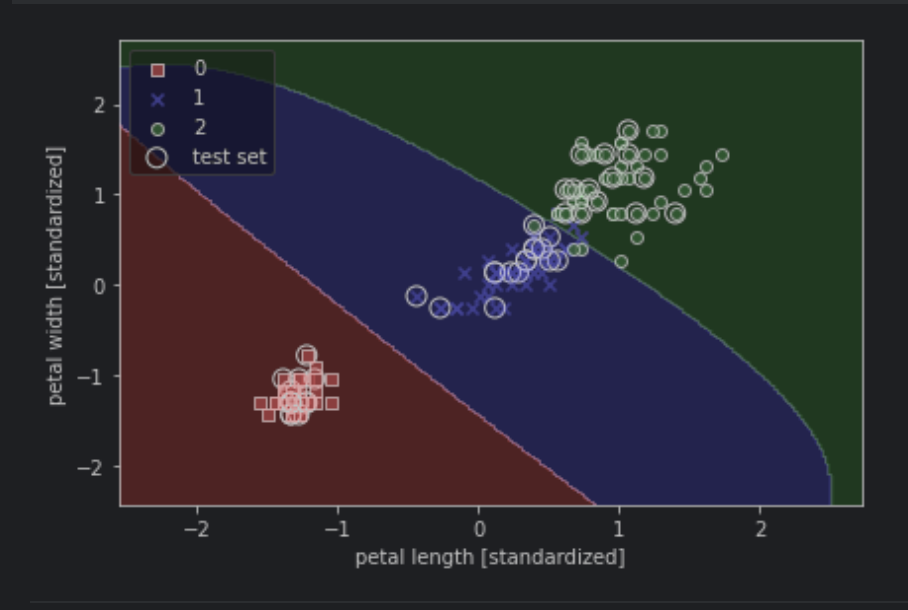
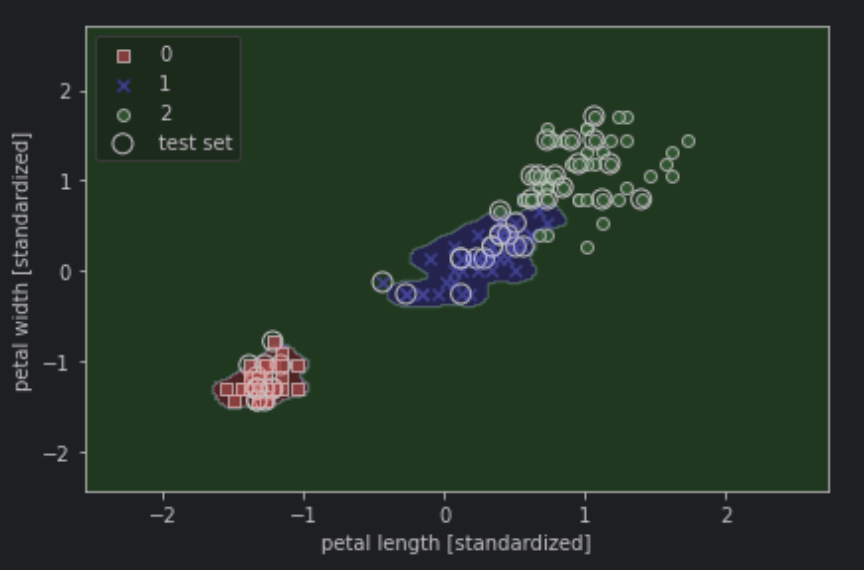

결정 트리는 훈련데이터에 있는 특성을 기반으로 샘플의 클래스 레이블을 추정할 수 있는 일련의 질문을 학습한다.
이때 트리를 구성하는 방식은 정보 이득이 최대가 되는 방향으로 구성한다.
불순도 지표를 이용하여 확인한다. 불순도가 낮을 수록 정보 이득이 커진다. 대표적인 불순도 지표는 다음과 같다.
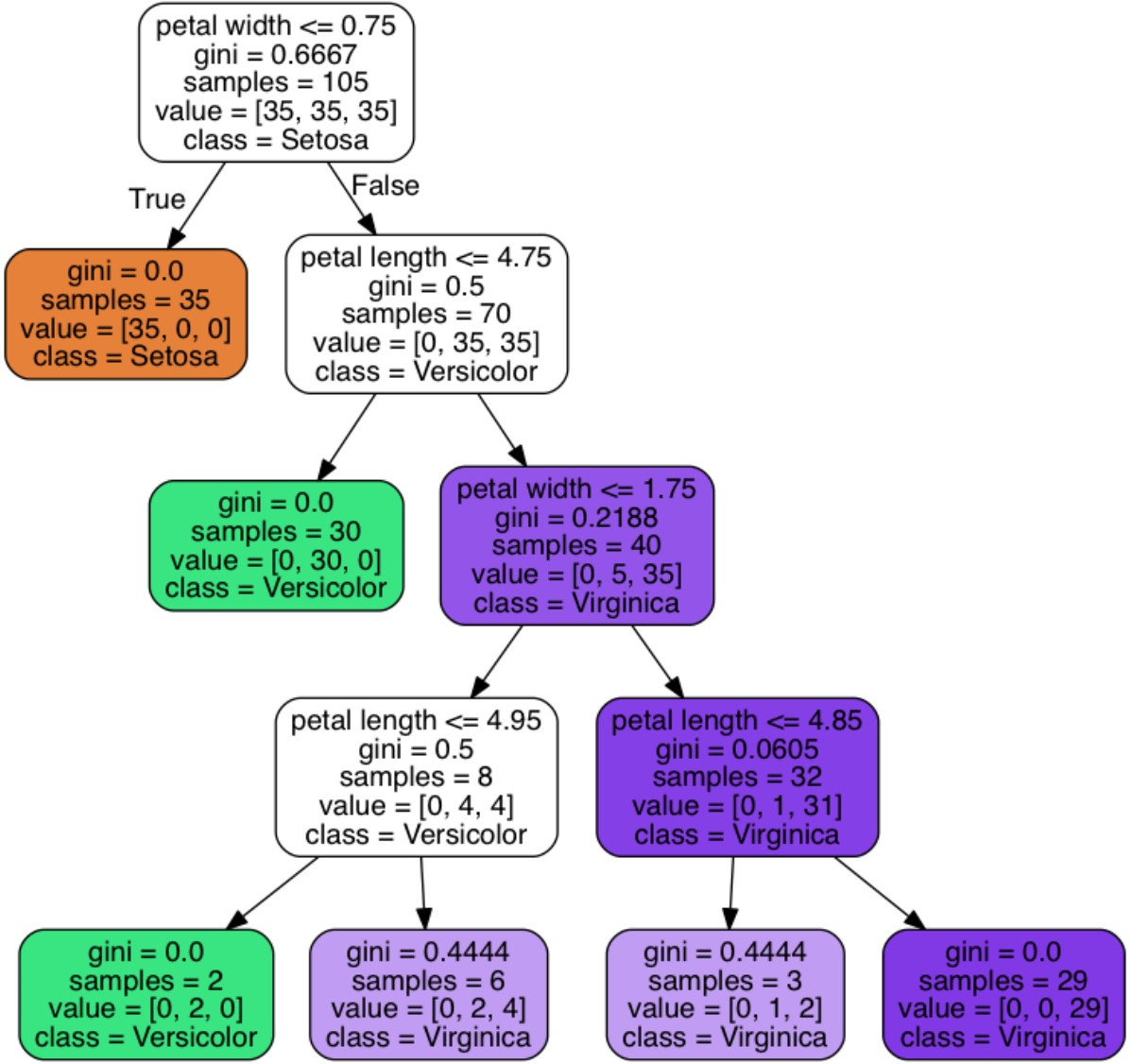
이런 식으로 결정 트리가 완성된다.
랜덤 포레스트는 결정 트리만큼 해석이 쉽지는 않지만 하이퍼파라미터 튜닝에 많은 노력을 기울일 필요가 없다.
모델 해석이 중요할 때는 결정트리가 사용하기 좋다.
로지스틱 회귀는 확률적 경사 하강법을 사용한 온라인 학습 뿐만 아니라 특정 이벤트 확률 에측에도 사용 가능
언어 모델이란, 결국에는 그 다음으로 어떤 단어가 오는 것이 가장 자연스러운지를 확률로 보고 가장 높은 확률의 단어를 선택해서 문장을 구성하는 방식이다. 위 포스트에서는 n…
2025/03/10
선형 회귀 모델에 대해 알아보자. 보스턴 집 가격 예측 문제를 예시로 들어서 설명하겠다.
2025/01/09
레이블이 없는 데이터들을 분석하여 비슷한 데이터들끼리 그룹으로 묶을 것이다.이를 군집으로 묶는다하여 클러스터링(clustering)이라 한다. - k-평균 알고리즘을 이용하여 클러스터 중심 찾기- 상향식 방법으로 계층적 군집 트리 만들기- 밀집도 기반의 군집 알고리즘을 사용하여 임의 모야을 가진 대상 구분하기
2025/01/09
딥러닝은 인공 신경망을 효과적으로 학습시키기 위한 머신러닝의 하�위분야이다. 아래 내용을 소개하겠다.- 다층 신경망 개념- 역전파 알고리즘- 이미지 분류를 위한 다층 신경망 훈련
2025/01/09

