Transformers
Seq2Seq에서 RNN을 아예 빼버리고 attention으로 구성해보면 어떨까? → Transformer의 구조 현재는 seq2seq + attention에서는 하나의 벡터로…
2025/04/27
NEW POST
Jinsoolve.
데이터 간의 순서가 중요한 데이터를 시퀀스 데이터라고 한다.
시퀀스 데이터를 처리해주기 위해서는 RNN(Recurrent Neural Network) 모델을 사용해서 처리해야 한다.
Sequence 데이터(순차 데이터)는 말 그대로 데이터들 간의 의존성(순서)이 있는 데이터다.
시계열 데이터(time series)은 이러한 seq 데이터의 한 종류다. time step 즉 시간 차원이 데이터 들 간의 순서를 결정하는 데이터다.
시계열이 아닌 seq 데이터로는 텍스트, DNA 등이 있다.
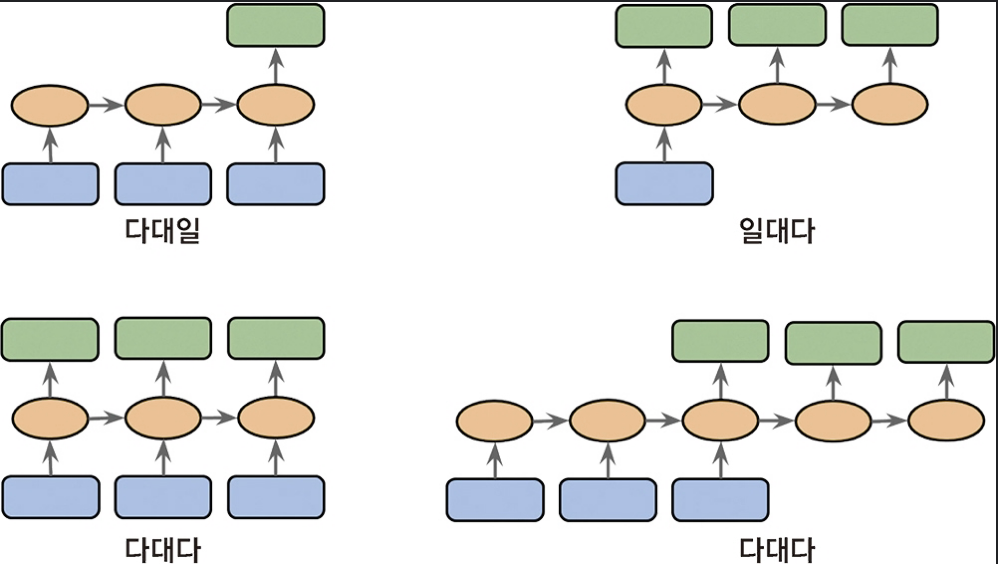
가 있다. 입력이나 출력 둘 중 하나가 시퀀스가 아니라 벡터나 스칼라 데이터일 수 있다.
데이터들끼리의 연관이 있는 시퀀스 데이터인 만큼 모델에도 이전 정보를 기억하고 연결시켜주는 모델이 필요하다. 이것이 RNN이다.
Recurrent Neural Network의 약자로, 재귀적으로 순환하는 신경망이다.

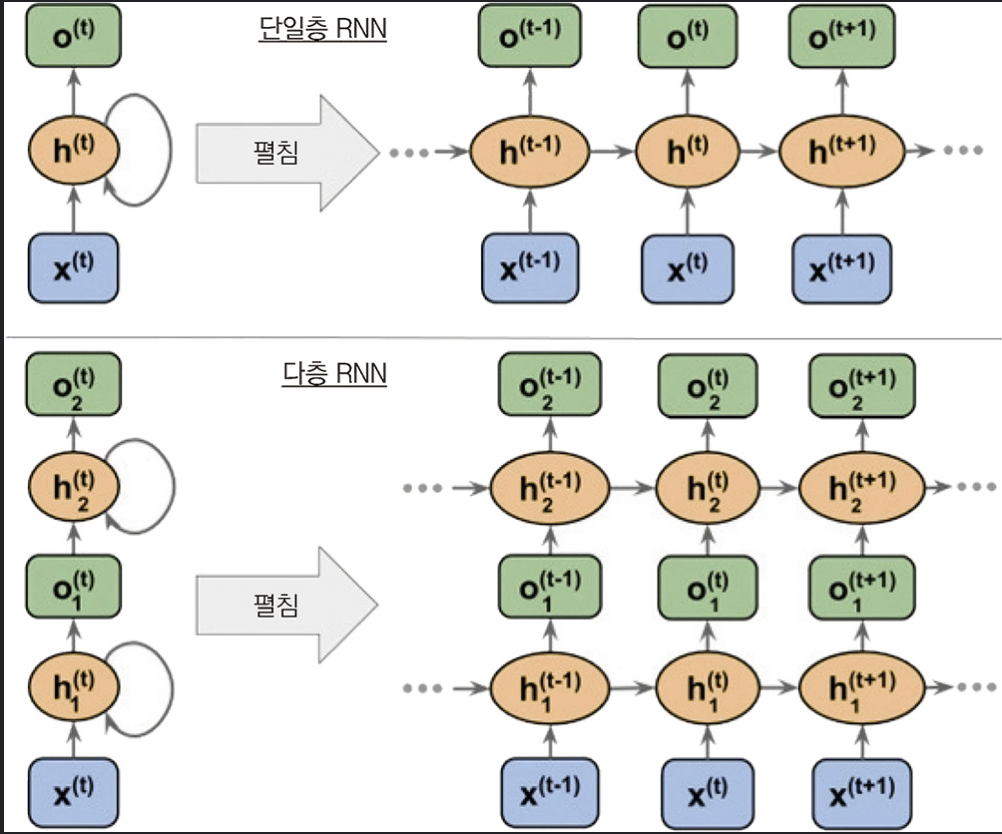
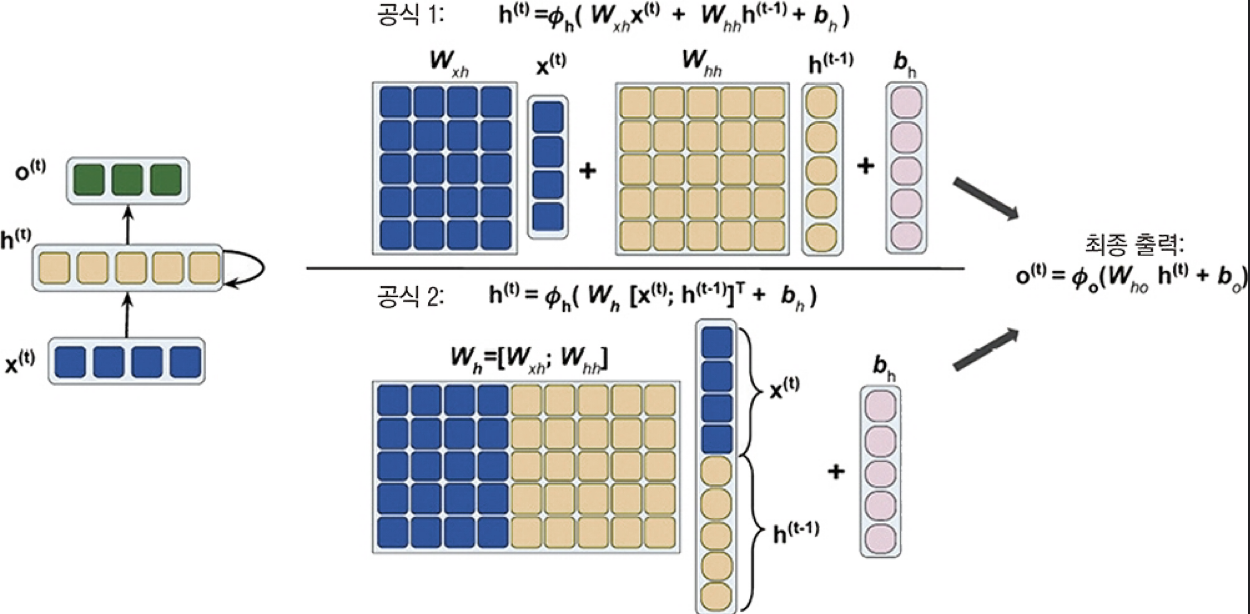
이런 식으로 하나의 은닉층이 입력층과 동시에 이전 은닉층의 값을 받는다.
계산은 다음과 같이 이루어진다.
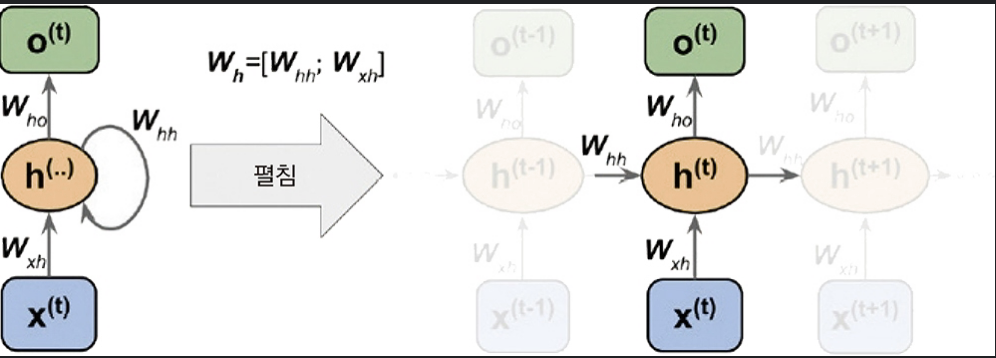
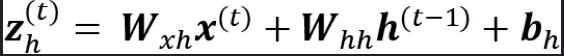
이 계산을 한번에 하기 위해 벡터로 연결하여 계산하면 다음과 같다.
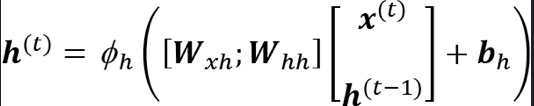
반면에, 은닉층이 아니라 출력층이 순환될 수도 있다. 아래 그림을 보자.
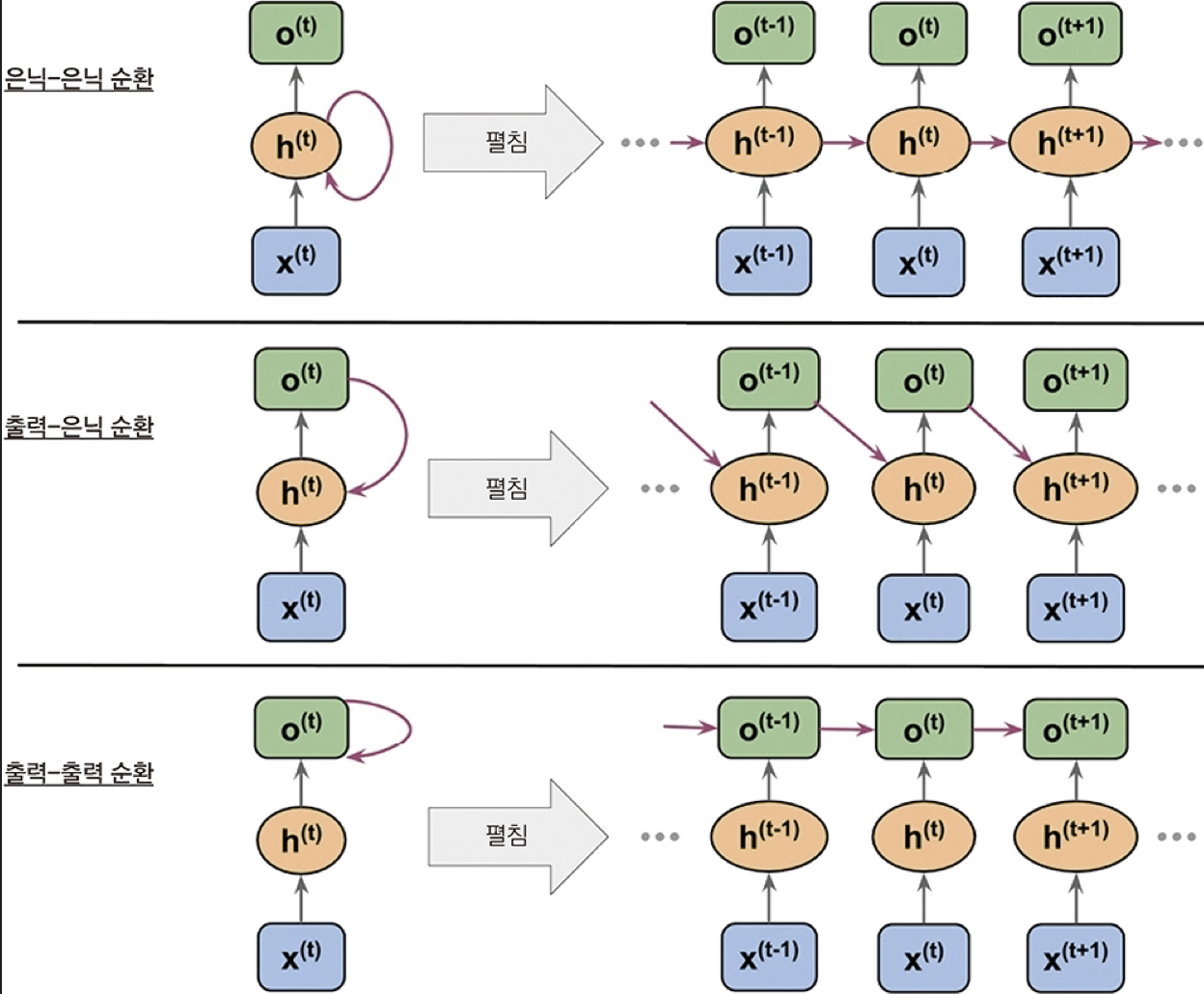
RNN의 문제가 시퀀스 데이터를 받다보니 모델이 깊어질 수 밖에 없는데, 모델이 깊어지면 따라오는 문제가 바로 Gradient Vanishing(or Exploding) Problem 이다.
이를 해결하기 위해 등장한 모델이 LSTM이다.
LSTM은 은닉층의 가중치의 값을 W=1로 적절히 조절하기 위한 메모리 셀이 존재한다.
이 메모리셀에는 다음과 같은 게이트들이 있다.
시그모이드 함수와 tanh 함수를 사용하여 활성화하거나 차단된다.
2014년에 GRU라는 새로운 방식이 소개되었다. LSTM 보다 구조가 단순하여 계산 효율성이 높다. 동시에 일부 작업의 성능은 LSTM과 견줄 만하다.
리뷰 문장을 가져와서 평점을 계산하는 모델을 구현해보겠다. 모델 구현의 순서는 다음과 같다.
문자형 데이터를 인코딩할 때 one-hot encoding을 사용한다. 하지만 one-hot encoding은 0이 굉장히 많게 인코딩되므로 차원이 커지고 이는 곧 차원의 저주()로 이어지고, 동시에 0이 대다수이므로 값이 sparse해지기 때문에 gradient vanishing을 야기시킨다.
이를 해결하기 위해 Embedding 기법을 사용한다. 임베딩은 실수값을 가진 고정된 길이의 벡터로 변환하는 기법이다.
tf.keras.layers.Embedding 을 사용한다.
여러 요인으로 인해 계산 효율성을 높이고 성능도 좋게 하기 위해서는 batch(훈련데이터)를 작은 mini-batch로 나눈다.
이떄 mini-batch화된 시퀀스 데이터를 효율적으로 텐서에 저장하기 위해서는 동일한 길이가 되어야 한다. 이를 위해 가장 긴 차원의 데이터의 길이로 padding을 해서 같은 길이로 만든다.
tensorflow의 padded_batch() 함수를 사용한다.
지금까지 배운 모델들은 모두 seq2seq을 기반으로 구현한 모델들이다. 하지만 2017년에 NeurIPS 논문에 Transformer라는 모델이 소개되었는데 성능이 굉장히 좋다.
Transformer의 핵심 원리는 입력과 출력 시퀀스 사이의 전역 의존성(어텐션)을 모델링하는 것이다.
쉽게 얘기하면 입력 단어�들 간의 의존성 즉, 관계(혹은 서로에 대한 중요도)를 가중치로 계산하여 출력 시퀀스를 만드는 것이다.
과정은 다음과 같다.
이러한 기법을 셀프 어텐션 메커니즘이라 한다.
이러한 셀프 어텐션 메커니즘을 여러 기법으로 좀 더 강화시킬 수 있다. 한 번 살펴보자.
기본적인 셀프 어텐션은 출력을 계산할 때 학습되는 파라미터를 전혀 사용하지 않았다.
이를 query, key, value 시퀀스를 이용하여 모델을 업데이트 시키는 메커니즘이다.
좀 더 자세히 설명해보면, 기존의 중요도 가중치 즉, 시퀀스간의 어떤 정도로 연관이 되어 있는지의 값을 해당 값을 ��통해 학습시키고 이를 조정한다.
여러 개의 셀프 어텐션 연산을 합친 멀티 헤드 어텐션이 있다.
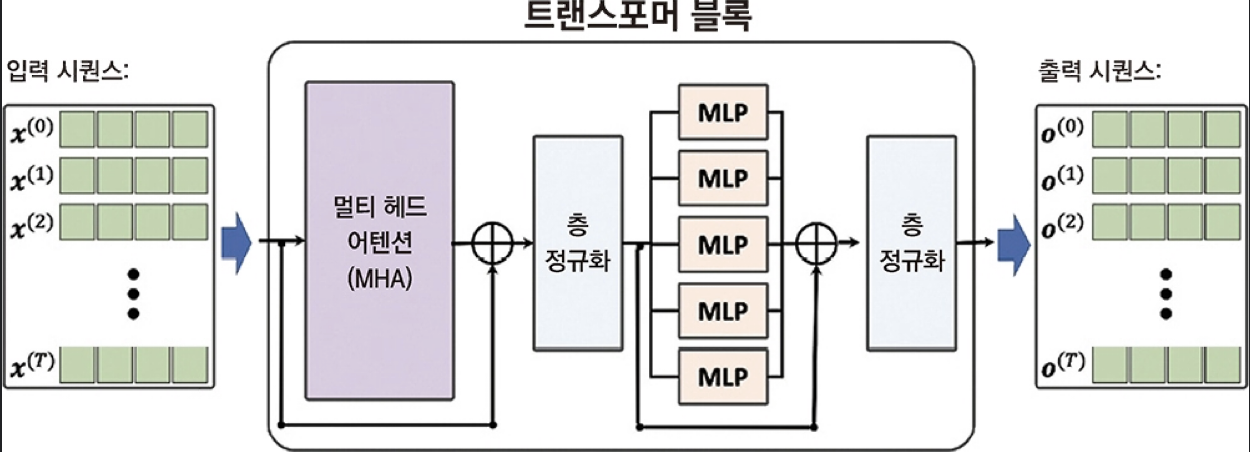
Residual Connection(or Skip Connection)은 깊은 신경망에서 얕은 레이어에서 깊은 레이어로 값을 전달하여 가중치를 조정하는 것이다. 이는 그레디언트 소실 문제를 완화시키고 학습을 좀 더 효율적으로 할 수 있도록 도와준다.
위의 멀티-헤드에서도 Res Connect이 사용되는데 이를 이용해 여러 개의 셀프 어텐션의 결과를 합친다.
Seq2Seq에서 RNN을 아예 빼버리고 attention으로 구성해보면 어떨까? → Transformer의 구조 현재는 seq2seq + attention에서는 하나의 벡터로…
2025/04/27
성# Language Model(LM)이란? 언어 모델이라는 건, 사실 다음에 올 단어를 확률로 예측하는 것이다. 이러한 언어 모델들을 어떻게 발전시켜왔는 지 살펴보자. 이미 이…
2025/04/27
이전 포스트에서 RNN에서 Vanishing Gradient로 인해 장기 의존성 문제가 있다는 사실을 이야기했다. 이런 Vanishing Gradient를 해결하기 위해 크게…
2025/04/27
기존 RNN의 병목 현상을 해결하기 위해 Attention이 등장했다. Decoder에서 한 단어를 예상할 때, 해당 단어와 특별히 관련되어 있는 Encoder의 특정 단어를…
2025/04/27



