Transformers
Seq2Seq에서 RNN을 아예 빼버리고 attention으로 구성해보면 어떨까? → Transformer의 구조 현재는 seq2seq + attention에서는 하나의 벡터로…
2025/04/27
NEW POST
Jinsoolve.
합성곱 신경망은 컴퓨터 비전을 위한 머신러닝 분야를 크게 발전시켰다.
CNN(Convolutional Neural Network)는 뇌의 시각 피질이 물체를 인식할 때 동작하는 방식에서 영감을 얻었다고 한다.
CNN은 low-level feature을 추출하는 것부터 시작해서 뒤쪽의 층으로 갈수록 high-level feature를 추출한다. 이미지를 픽셀 패치 단위로 나누어서 각 특징에 대해 학습하고 모든 가중치에 대해 업데이트 한다.
이는 희소 연결과 파라미터 공유 특성으로 인해 이미�지 분류에 있어서 꽤나 효과적이다.
CNN에서 이 특징을 추출하는 방식은 합성곱이다. 합성곱층과 서브샘플링(풀링)층, 완전 연결(FC)층을 이용해서 특징을 추출하고 파라미터를 학습시킨다.
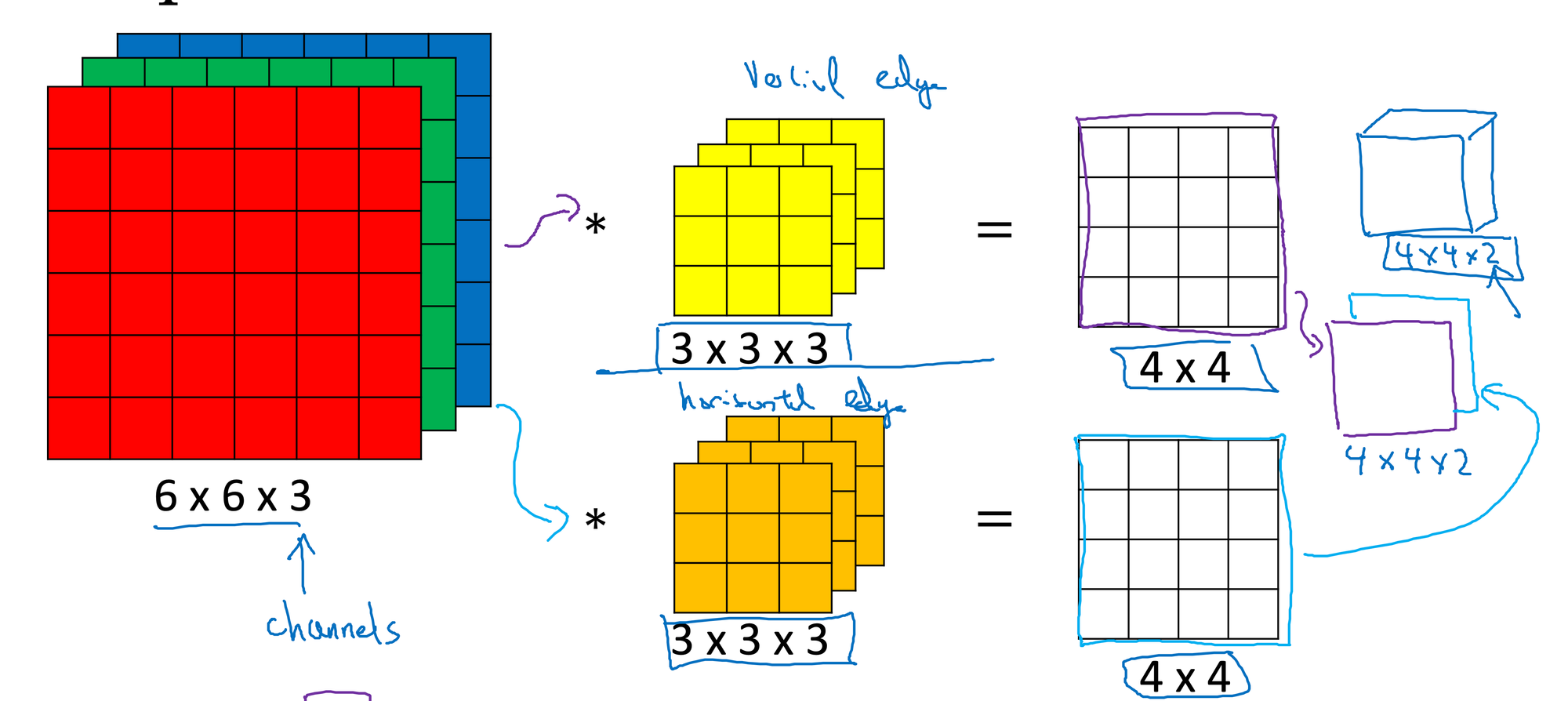
위 그림은 3D 합성곱에 대한 설명이다. 합성곱은 padding, stride 값을 이용해 결과 층의 차원을 조절할 수 있다.
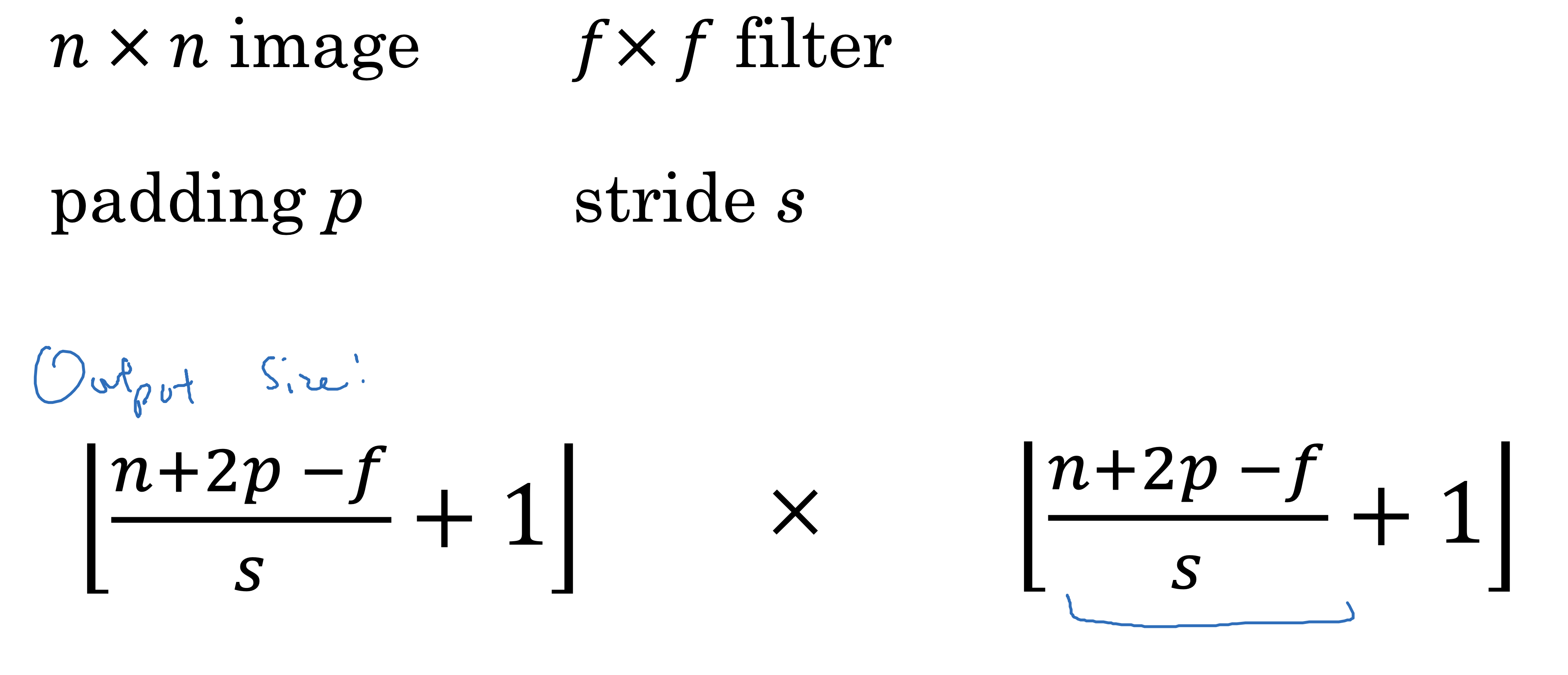
결과 층의 차원은 다음과 같다.
서브샘플링에는 두 종류의 풀링 연산이 있다.
max-pooling, average-pooling(mean-pooling)
전통적으로 풀링은 겹치지 않는다고 가정한다. 따라서 스트라이드의 크기를 풀링의 크기와 같이 설정한다.
특성 맵의 크기를 줄이기 위해 풀링층을 사용하는 대신 스트다리이드 2인 합성곱 층을 사용하기도 한다.
은닉층의 특정 은닉유닛을 랜덤하게 비활성화시켜 과대적합을 막는 기법이다. 주로 뒤쪽의 은닉층에 적용한다.
드롭아웃의 랜덤성에 따른 모델의 결과차이로 인해 앙상블 모델의 효과를 내기도 한다.(하지만 드롭아웃과 앙상블과의 관계가 아주 분명하지는 않다. 다만 그렇게 해석될 여지가 있다 정도로 보자.)

분류를 위한 손실함수는 위와 같은 종류가 있다.
데이터 증식 기법은 이미지 분류 모델에서 데이터의 양을 늘려서 훈련성능을 높이기 위해 사용하는 기법이다.
데이터를 자르거나 뒤집거나, 대비, 명도, 채도 등을 바꾼다.
tf.image에서 crop_to_bounding_box(), flip_left_right(), adjust_contrast(), adjust_brightness() 등 다양한 augmentation 함수들이 있다.
모델을 형성하는 건 Sequential API를 이용해서 했다.
Seq2Seq에서 RNN을 아예 빼버리고 attention으로 구성해보면 어떨까? → Transformer의 구조 현재는 seq2seq + attention에서는 하나의 벡터로…
2025/04/27
성# Language Model(LM)이란? 언어 모델이라는 건, 사실 다음에 올 단어를 확률로 예측하는 것이다. 이러한 언어 모델들을 어떻게 발전시켜왔는 지 살펴보자. 이미 이…
2025/04/27
이전 포스트에서 RNN에서 Vanishing Gradient로 인해 장기 의존성 문제가 있다는 사실을 이야기했다. 이런 Vanishing Gradient를 해결하기 위해 크게…
2025/04/27
기존 RNN의 병목 현상을 해결하기 위해 Attention이 등장했다. Decoder에서 한 단어를 예상할 때, 해당 단어와 특별히 관련되어 있는 Encoder의 특정 단어를…
2025/04/27



